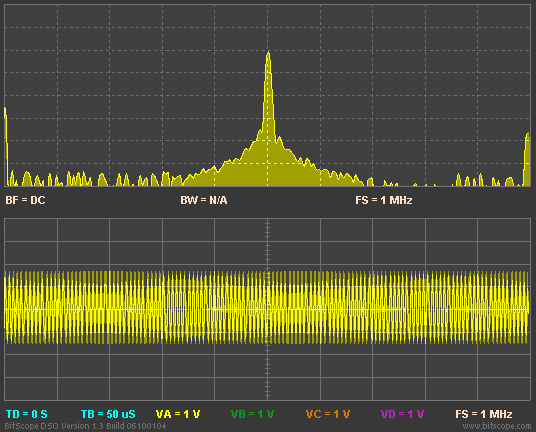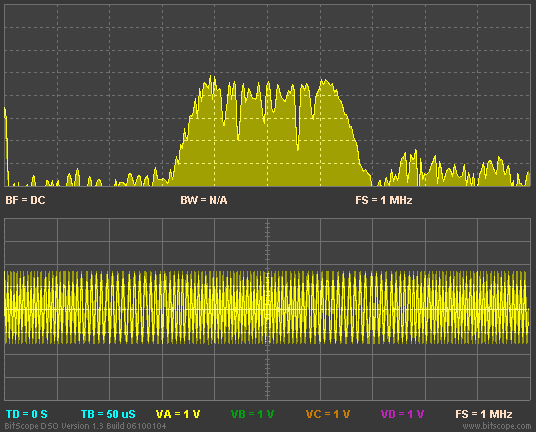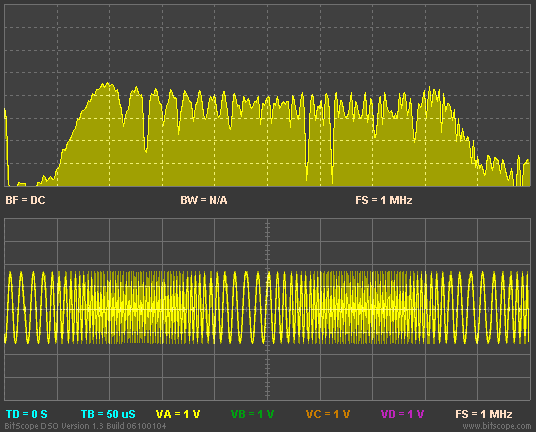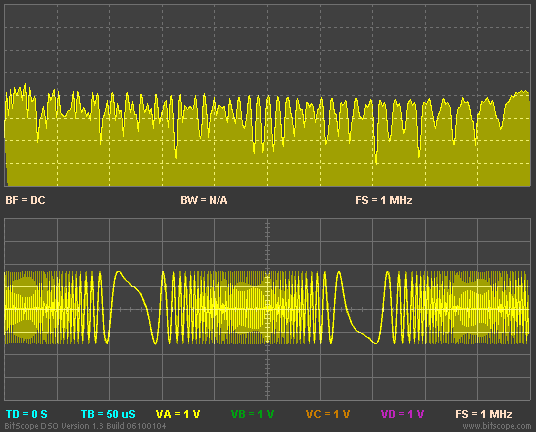
I see SoundandMotion has shown exactly how much misinformation Amir spreads in his posts
As can be quite clearly seen the imaginary numbers are involved in both FFT magnitude AND phase
Your statement is totally false yet again, Amir!!
SoundandMotion said:amirm said:The imaginary component of the complex numbers show the phase which we don't care about. What is shown is just the "real" component which represents the amplitude of the basis function. We don't need to maintain the phase because we don't need to invert back to time domain.
DonH56 said:Hmmm... While admitting I have not followed too closely lately (work and Life issues), I rarely use just real or imaginary data alone unless looking for a reactive component. The magnitude reported in an FFT is normally the RSS of real and imaginary data. The magnitude of a complex number is not accurately given by just the real (or imaginary) component; the magnitude is affected by each. I must have missed something crucial...
No, I don't think you missed anything.
Magnitude = sqrt(re(FFT)^2 + im(FFT)^2) = sqrt(FFT * conj(FFT))
Phase = arctan(im(FFT)/re(FFT))
As can be quite clearly seen the imaginary numbers are involved in both FFT magnitude AND phase
Your statement is totally false yet again, Amir!!
Last edited: